치열해지는 데이터 전쟁 시대의 데이터 관리와 보안 전략
2025.10.30

흔히 데이터는 21세기의 원유라고 합니다. 이 표현은 2011년, 시장조사기관 가트너(Gartner)가 데이터 경제의 중요성을 강조하며 사용한 비유입니다. 당시 전 세계는 머신러닝/딥러닝 알고리즘이 활발히 등장했고, 가용한 컴퓨팅 리소스의 확대로 데이터 활용이 기하급수적으로 늘어나던 시기였습니다.

*출처: The oil of the 21st century
약 15년이 지난 요즘, 데이터의 석유에 대한 비유는 이제 익숙함을 넘어 진부하게 느껴지기까지 합니다. 그렇다면 ‘데이터는 21세기 원유다’라는 표현은 아직도 유효할까요? 정답은 ‘그렇다’ 입니다. 스케일링 법칙(Scaling Law)으로 대표되는 초거대언어모델(LLM) 개발 경쟁과 함께 시작된 아키텍처와 인프라의 발전과 함께 도래한 생성형 AI의 시대에, 데이터는 단순한 분석을 넘어 생성형 AI 모델의 핵심이 되며 그 중요성이 점점 더 증가하고 있습니다.
이미 전 세계 테크 기업들은 데이터 확보 전쟁에 돌입했습니다. 아마존, 마이크로소프트, 구글, 세일즈포스와 같은 빅테크들은 자신들이 다년간 축적해 온 방대한 데이터를 핵심 경쟁력으로 인식하며, 외부 접근을 차단하고 자사 생태계 안에 데이터를 묶어두려는 움직임을 보이고 있습니다. 아마존은 오픈AI, 퍼플렉시티, 클로드 등의 AI 에이전트가 자사 쇼핑 데이터를 크롤링하지 못하도록 사실상 데이터 장벽을 쌓고 있고, 세일즈포스는 슬랙 메시지 데이터에 대한 제3자 접근을 제한하기도 했습니다.

*출처 : business insider
이는 단순한 보안 조치가 아니라, 데이터가 곧 AI 경쟁력이 된 시대에 자사 데이터 자산을 보호하고 수익화하려는 전략적 대응이라 할 수 있습니다. 결국 이러한 데이터 봉쇄 현상은 AI 혁신의 속도를 좌우할 새로운 권력 균형을 만들고 있으며, 기업들은 생존을 위해 데이터를 어떻게 확보하고 관리할 것인지에 대한 근본적인 전략 전환을 요구받고 있습니다.
데이터 자체가 한 기업이나 개인의 정체성을 대표하게 된 생성형 AI의 시대를 맞이한 지금, 효과적인 데이터 관리는 선택이 아닌 필수가 되었습니다. 관리의 영역에서 효과적으로 데이터 확보를 위한 파이프라인 구축 및 마이그레이션(Migration)뿐만 아니라, 보안 역시 중요합니다. 이번 시간에는 점점 더 치열해지는 AI 시대에, 데이터를 확보하고 생존해 나가기 위한 기업들의 전략에 대해 알아보도록 하겠습니다.
데이터 관리의 핵심 노하우 – 데이터 파이프라인 구축 및 마이그레이션이란?
데이터 파이프라인(Data Pipeline)이란, 데이터를 수집(ingestion), 저장(storage), 처리(processing), 활용(usage)에 이르기까지 일련의 과정을 자동화하고 체계적으로 관리하는 흐름을 말합니다. 쉽게 말해, 기업 내·외부에서 생성되는 다양한 데이터를 목적에 맞게 끊김이 없이 전달하고 정제하는 데이터 공급망입니다. 예를 들어 고객 로그, IoT 센서 데이터, 음성·이미지 데이터 등이 파이프라인을 통해 실시간으로 수집되고, 전처리와 변환 과정을 거쳐 데이터 레이크나 웨어하우스에 저장된 뒤 AI 모델 학습이나 비즈니스 인사이트 도출에 활용됩니다.
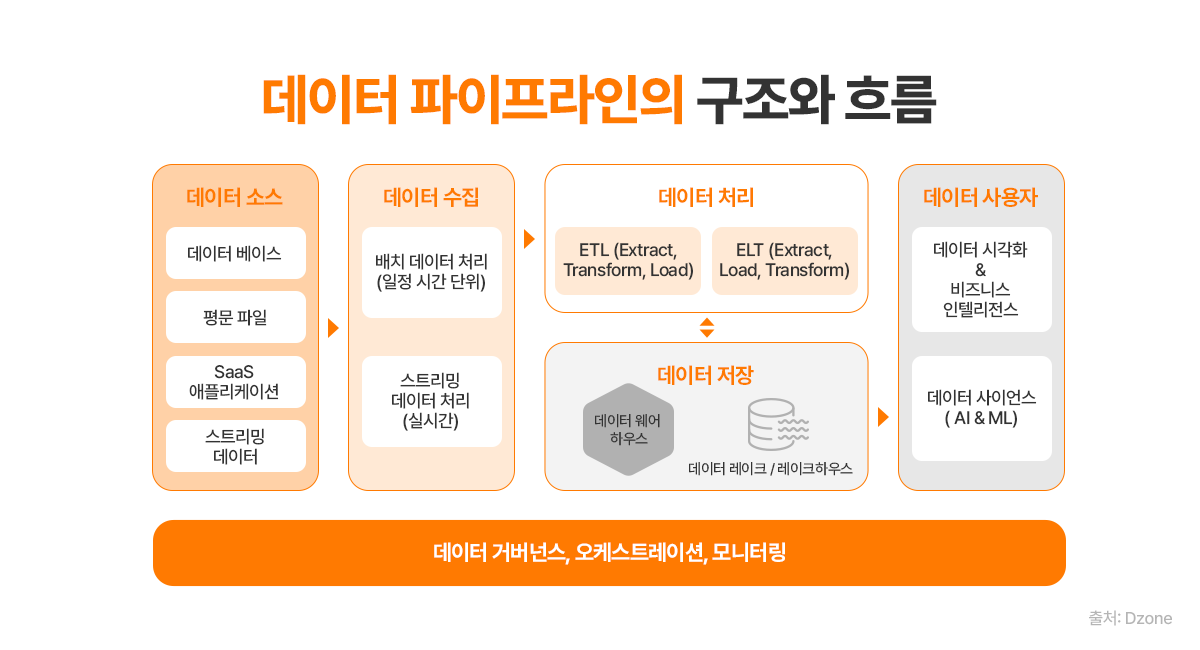
이 과정에서 중요한 것은 자동화와 확장성, 그리고 품질 관리입니다. 데이터가 많아질수록 수동 관리로는 일관성과 신뢰성을 확보하기 어렵기 때문에, 기업들은 Apache Airflow나 Azure Data Factory, AWS Glue 같은 워크플로우 오케스트레이션 도구를 활용해 파이프라인을 자동화하고 있습니다. 또한, 데이터 품질(Data Quality) 모니터링을 통해 오류나 중복을 최소화하고, 모델 학습이나 분석에 적합한 형태로 데이터를 지속적으로 최적화해야 합니다.
한편, 데이터 마이그레이션(Migration)은 기존 시스템에 저장된 데이터를 새로운 환경으로 이전하는 과정을 의미합니다. 이는 온프레미스(On-premise) 환경에서 클라우드로 옮기거나, 레거시 데이터베이스에서 최신 데이터 레이크/웨어하우스로 전환하는 경우가 대표적입니다.
데이터 마이그레이션이 필요한 경우는 다양합니다.
1) 시스템 노후화: 기존 데이터베이스나 스토리지의 성능이 한계에 도달해 더 이상 최신 애플리케이션을 지원하지 못할 때
2) 클라우드 전환(Cloud Migration): 유연한 확장성, 비용 효율성, 글로벌 접근성을 확보하기 위해 온프레미스 데이터를 클라우드 환경으로 이전할 때
3) 데이터 통합 및 표준화: 여러 부서나 시스템에 분산된 데이터를 통합하여 일관된 데이터 거버넌스를 구축할 때
4) AI/ML 환경 구축: 대규모 학습 데이터셋을 확보하거나 고성능 분석을 위해 데이터 레이크, 데이터브릭스(Databricks), Snowflake 등 최신 플랫폼으로 옮길 때
5) 보안 및 규제 대응: 데이터 보호법이나 내부 보안정책에 따라 더 안전한 인프라로 데이터를 이동해야 할 때
데이터 마이그레이션은 단순한 이동이 아닙니다. 데이터 구조와 스키마를 새 환경에 맞게 재설계하고, 보안·거버넌스·규제 요건을 모두 충족시키는 고난도의 작업입니다. 특히 생성형 AI 시대에는 모델 학습용 데이터의 대규모 이동과 정제가 빈번하게 일어나므로, 안정적이고 안전한 데이터 마이그레이션 체계가 경쟁력의 핵심으로 떠오르고 있습니다.
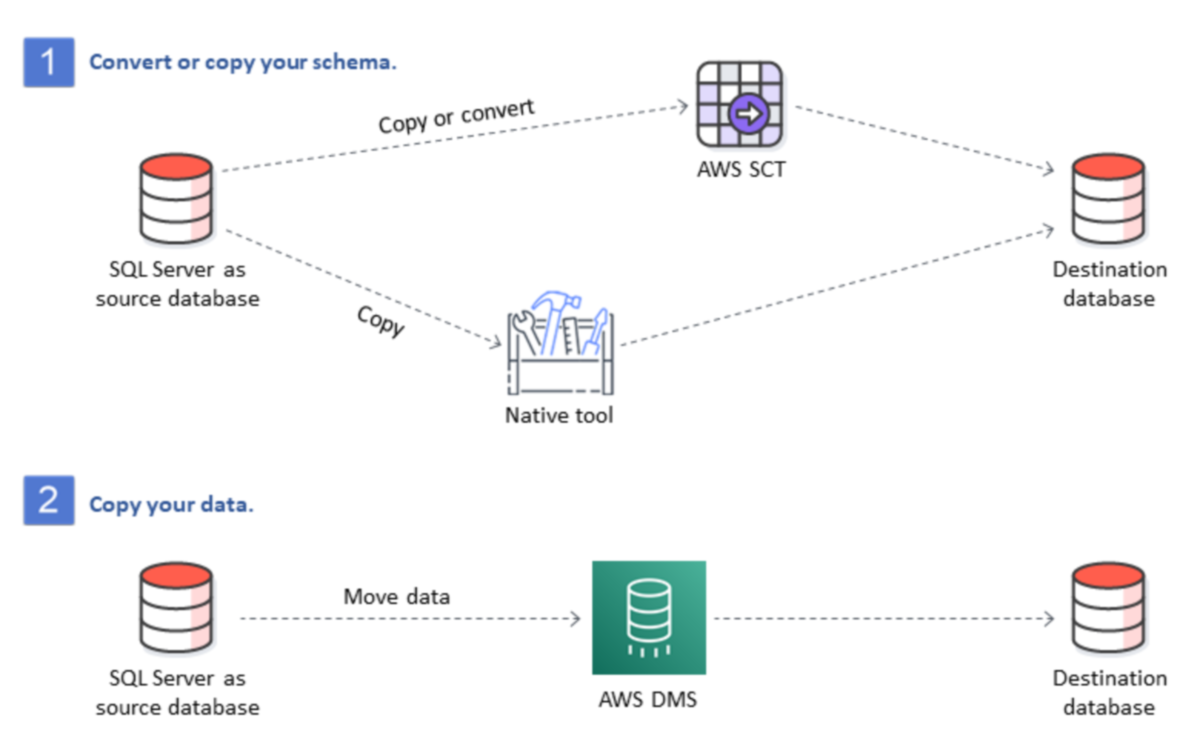
결국 데이터 파이프라인 구축과 마이그레이션은 AI 혁신의 숨은 인프라입니다. 데이터를 얼마나 효율적이고 신뢰성 있게 이동·관리하느냐가 곧 기업의 AI 경쟁력을 좌우합니다. 따라서 기업은 단순히 데이터를 보유하는 데 그치지 않고, 끊임없이 흐르고 진화하는 자산으로 관리하는 전략적 역량을 확보해야 합니다.
치열해지는 AI 시대, 데이터 전쟁의 서막과 보안
데이터가 기업 경쟁력의 원천이 된 만큼, 이를 지키기 위한 보안(Security)과 거버넌스(Governance)는 선택이 아닌 생존의 문제가 됐습니다.
특히 생성형 AI의 등장으로 내부 문서, 고객 데이터, 소스코드 등 민감한 정보가 AI 모델 학습이나 외부 서비스 연동 과정에서 노출될 위험이 커졌습니다. 실제로 다수의 글로벌 기업들이 사내 직원이 AI 챗봇에 입력한 정보를 통해 내부 비밀이 유출되는 사고를 겪기도 했습니다. 이에 따라 기업들은 데이터 접근 정책을 강화하고 자체 AI 플랫폼을 구축하는 방향으로 전략을 전환하고 있습니다.
이제 보안의 초점은 ‘접근 차단’을 넘어 ‘지능형 데이터 통제(Intelligent Data Control)’로 이동하고 있습니다. 데이터는 완전히 닫아두면 활용 가치가 사라지고, 완전히 열면 보안이 무너집니다. 따라서 기업들은 민감도 기반 분류(Classification), 암호화(Encryption), 접근권한 관리(Role-based Access Control), 그리고 AI 모델 학습용 데이터에 대한 차등적 비식별화(Differential Privacy) 기술을 통해 활용성과 보안성을 동시에 확보하기 위해 시도하고 있습니다.
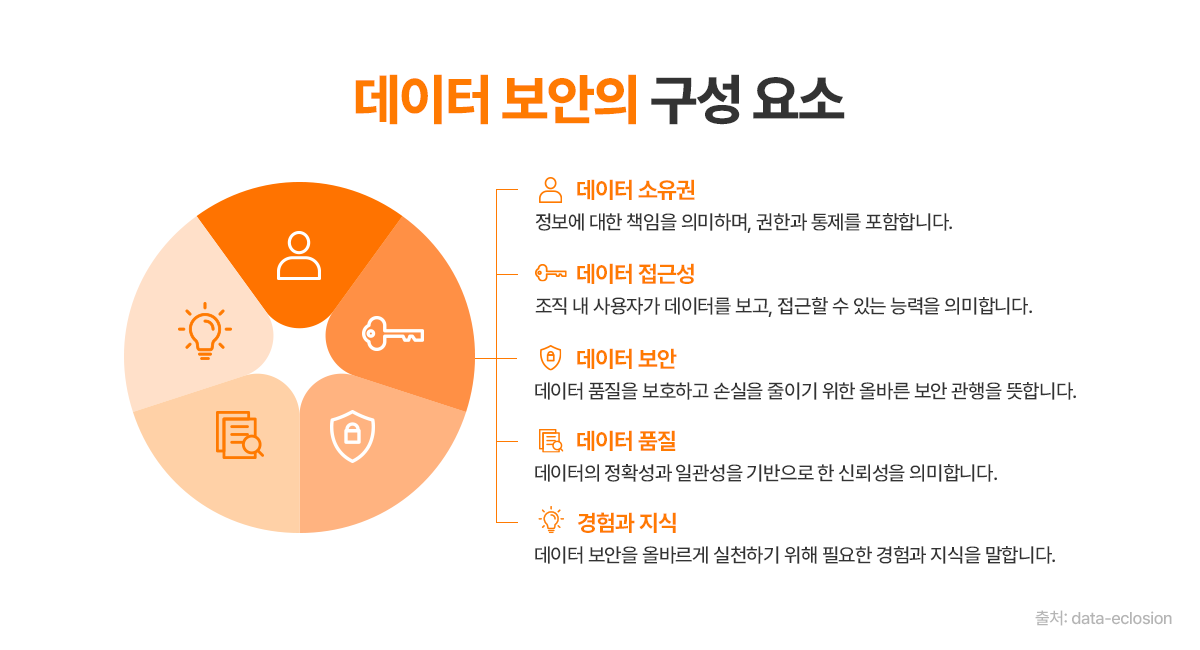
또한, 글로벌 규제 환경 역시 강화되고 있습니다. 유럽의 GDPR(General Data Protection Regulation), 미국의 CCPA(California Consumer Privacy Act), 한국의 개인정보보호법 개정안 등은 데이터 수집·이용·이전 전 과정에 대한 투명성과 통제권을 기업에 요구하고 있습니다. 이로 인해 많은 조직이 데이터 파이프라인을 구축할 때부터 규제 대응을 고려한 설계(Regulatory-by-Design)를 적용하고 있으며, AI 학습용 데이터셋 또한 사전 동의, 로그 추적, 삭제 요청 대응 등 규정 준수 프로세스와 함께 관리하고 있습니다.
결국 AI 시대의 데이터 보안은 단순히 방화벽이나 접근제어의 문제가 아니라, 데이터의 전 생애주기(Lifecycle) 전반을 통합적으로 관리하는 문제입니다. 수집 단계의 안전성, 전송 구간의 암호화, 저장소의 무결성, 활용 단계의 윤리성까지 모두 연결되어야 진정한 보안 체계가 완성됩니다.
이제 데이터는 더 이상 단순한 자산이 아니라, 기업의 정체성과 지적 자본을 대표하는 생명선입니다. 데이터 파이프라인과 마이그레이션을 통해 데이터를 효율적으로 이동·관리하는 것이 혈관이라면, 보안과 거버넌스는 그 혈관 속 데이터를 안전하게 순환시키는 면역 체계(Immune System)라 할 수 있습니다. AI가 발전할수록 이 면역 체계를 얼마나 견고히 구축하느냐가, 곧 기업의 지속 가능성과 신뢰도를 결정짓게 될 것입니다.
AI 혁신을 지탱하는 진짜 경쟁력, 데이터 운영 역량
생성형 AI 시대의 경쟁은 알고리즘과 모델의 우열이 아니라, 데이터의 질과 흐름을 얼마나 정교하게 설계하고 지켜내느냐의 경쟁력으로 옮겨가고 있습니다. 생성형 AI가 폭발적으로 성장할수록, 기업은 데이터를 지속적으로 순환·진화하는 자산으로 관리해야 합니다.
이를 위해서는 데이터 파이프라인을 통해 데이터의 이동 경로를 명확히 설계하고, 마이그레이션으로 변화하는 환경에 유연하게 대응하며, 보안·거버넌스를 통해 그 모든 흐름을 안전하게 통제하는 데이터 생태계를 구축이 필요합니다. 이러한 체계적 데이터 운영 역량이 향후 모든 산업의 디지털 전환과 AI 혁신을 뒷받침하는 핵심 기반이 될 것입니다.
[참고 자료]
– The oil of the 21st century, (Antonio Tramontano’s Linkedin Article)
– aws, (Heterogeneous database migration for SQL Server)
– Businessinsider, (Employees at firms like Amazon and Salesforce say company efforts to -retain them amid the Great Resignation don’t go far enough to tackle uneven compensation and low morale)
– Dzone, (An Overview of Data Pipeline Architecture)
– Data-eclosion, (Data security: the role of data governance)
AX 컨설팅부터 비즈니스 모델 발굴까지
Global Top 10 AX Service Company|SK AX




#데이터관리 #데이터보안 #데이터 #생성형AI #보안전략 #데이터전략 #데이터파이프라인 #마이그레이션



