고도화되는 AI 시대 속 할루시네이션을 방지하는 방법
2025.08.21

얼마 전 Google에서 고난도의 추론 및 대규모 코드 이해와 코딩 등에 강점을 지닌 Gemini-2.5-pro를 출시한 데 이어, OpenAI에서 일명 ‘박사급 생성형 AI’로 평가되고 있는 GPT-5를 대중에게 공개하면서 생성형 AI 모델에 대한 관심이 더욱 커지고 있습니다. 이처럼 생성형 AI 모델이 발전에 발전을 거듭하면서 고도화된 LLM을 누구나 저렴한 가격에 활용할 수 있는 길이 열리고 있습니다.
하지만 기술의 발전과 함께 해결해야 할 문제도 생기기 마련입니다. 최첨단 SoTA(State-of-The-Art) 초거대언어모델(Large Language Model, LLM) 활용의 진입장벽이 낮아지면서 실제로 존재하지 않는 정보를 그럴듯하게 꾸며내거나 부정확한 정보를 제공하는 할루시네이션(Hallucination), 즉 환각 현상이 중요 문제로 부각되고 있습니다.
사실 할루시네이션은 2022년 말 챗GPT가 처음 등장했던 시절부터 존재했던 개념으로, ‘세종대왕 맥북 던짐 사건’처럼 AI가 지어낸 허구 사례가 화제가 되면서 이미 익숙해진 개념입니다. LLM의 성능이 수년 전과는 비교할 수 없을 정도로 크게 개선된 지금도 여전히 할루시네이션 현상은 AI 연구자와 엔지니어들에게 해결해야 할 중요한 과제로 남아 있습니다.
이처럼 할루시네이션 현상은 생성형 AI 발전 과정에서 가볍게 넘길 수 있는 헤프닝이 아니라 LLM의 본질적인 현상의 하나라고 할 수 있습니다. 특히 AI 에이전트 개발과 같이 다양한 입력값(Input)에 대해 일정한 수준의 출력값(Output)을 내는 것이 필수적인 환경에서는 할루시네이션 현상을 시스템적으로 제어하는 기술과 노하우가 중요합니다. 이번 시간에는 할루시네이션의 원인과 해결 방안에 대해 분석해 보고 이에 대한 해결책에 대해 알아보도록 하겠습니다.
할루시네이션의 원인: LLM의 작동원리와 불완전한 데이터
할루시네이션 현상은 도대체 왜 발생하는 것일까요? 할루시네이션 방지를 위한 기술적 해결책을 논하기에 앞서, 그 원인을 깊이 이해하는 것이 중요합니다. 언뜻 보면 LLM이 단순히 거짓말을 하는 것처럼 보이지만, 사실 할루시네이션은 LLM의 근본적인 작동 방식에서 비롯된 현상이기 때문입니다.
LLM의 할루시네이션은 크게 데이터에 의한 것과 학습 및 추론 과정에서 발생하는 것으로 나눌 수 있습니다. 대부분의 LLM은 통계학적으로 방대한 텍스트 데이터를 사전 학습한 뒤, 이전 단어에 기반해 다음 단어를 순방향으로 예측하는 자기회귀(Autoregressive) 방식으로 작동합니다. 이러한 LLM의 작동 원리 때문에 최종 답변이 훈련 데이터와 학습 방식에 큰 영향을 받을 수밖에 없는 것입니다.
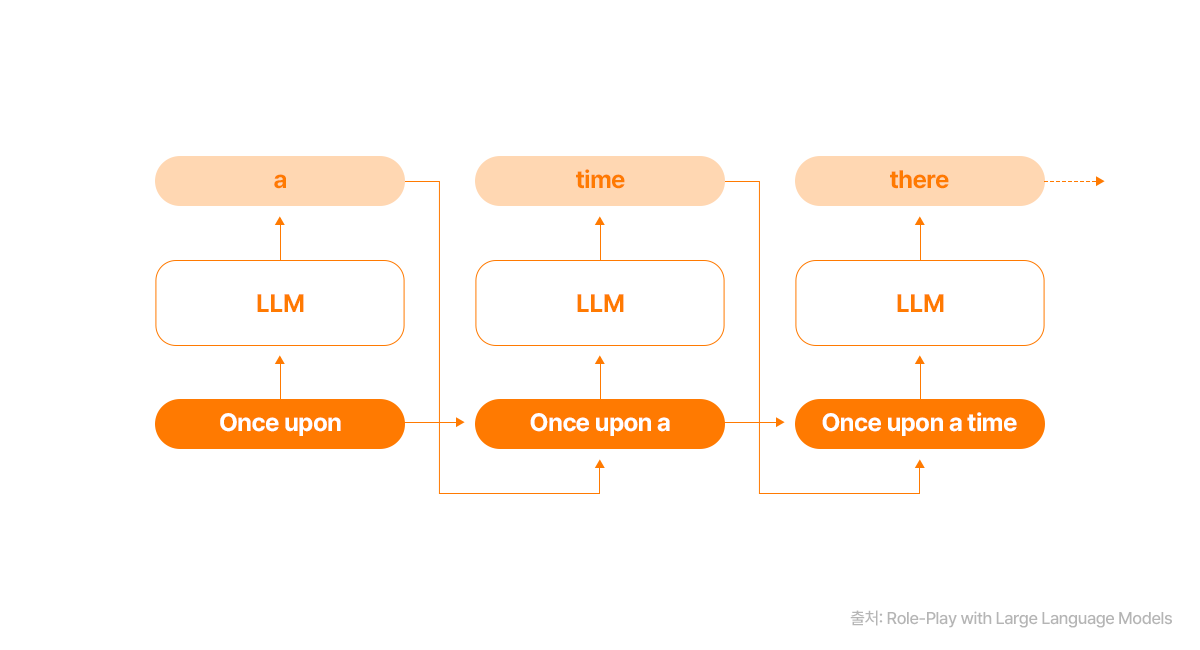
따라서 LLM이 불충분하거나 결함이 있는 데이터로 학습된 경우, 모델은 제한된 이해를 바탕으로 답변을 생성하거나 허위 정보가 포함된 데이터를 학습하여 사실과 다른 내용을 만들어낼 수 있습니다. 또한, 특정 지역이나 언어에 대한 데이터가 부족할 때도 할루시네이션이 발생합니다. 이는 같은 질문을 한국어와 영어로 했을 때 답변의 질이 달라지는 현상으로 나타나기도 합니다.
불완전한 데이터의 대표적인 사례로 편향(Data Bias)을 생각해 볼 수 있습니다. 훈련 데이터에 성별, 정치 성향 등 특정 편향이 존재하면 LLM은 이를 반영한 답변을 생성하게 되고, 이는 사회적 편견이나 차별을 조장할 수 있습니다.
예를 들어, 2023년 8월 미국의 워싱턴포스트에서는 정치적 중립을 표방하는 ChatGPT나 LLaMA2와 같은 LLM이 사실은 특정 정치 성향을 띄고 있다는 분석을 내놓았습니다. 영국 이스트앵글리아 대학의 연구 사례에 따르면, 각기 다른 LLM에게 정치 및 경제 문제에 대한 62가지의 질문을 던지고 긍정 혹은 부정으로 답하도록 지시했을 때, 뚜렷하게 다른 답변의 차이를 보였다고 합니다. 연구에 따르면 ChatGPT는 진보적인 성향의 답변을 많이 내놓았던 반면, LLaMA2의 답변은 보수에 가까운 경향성을 보였다고 합니다.
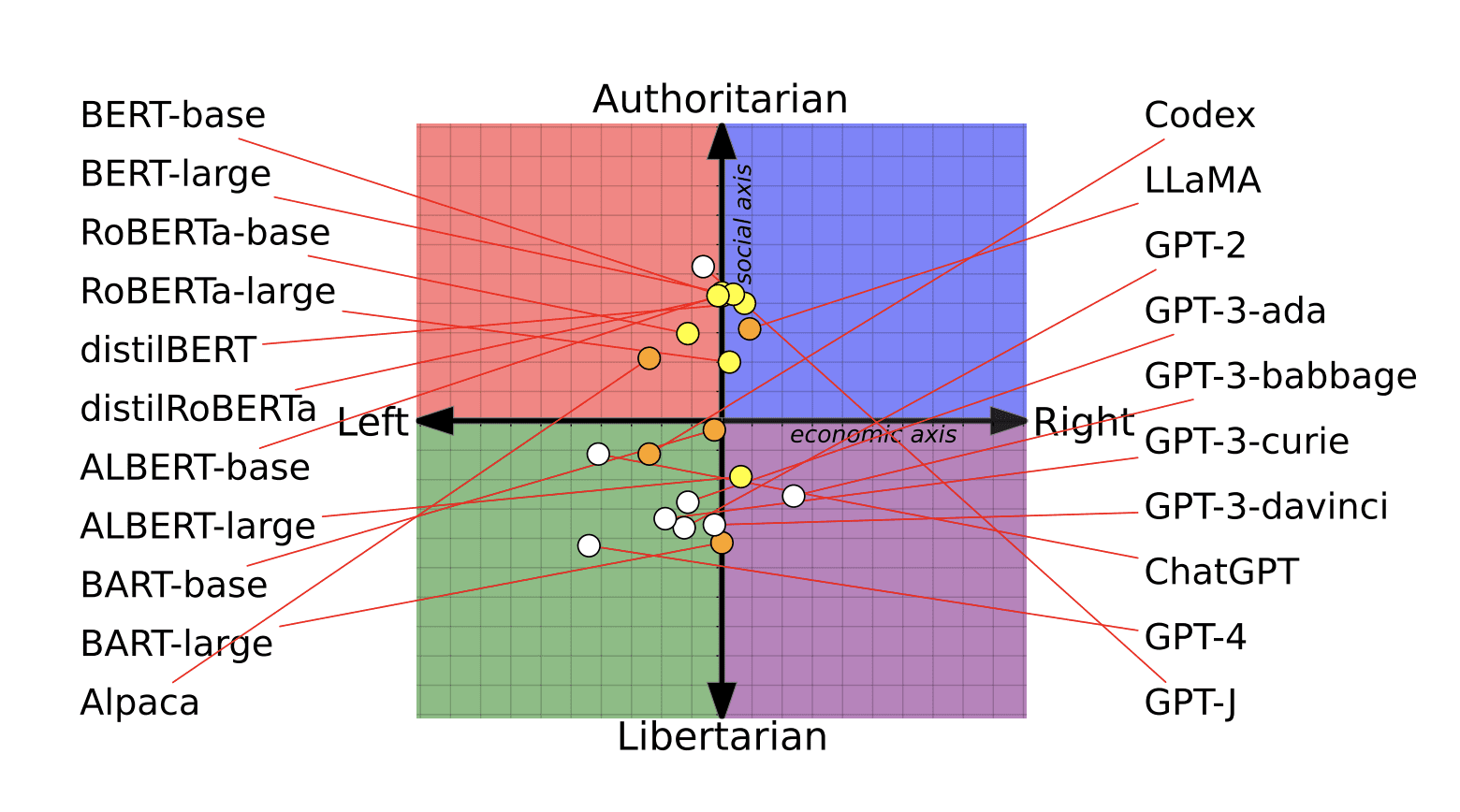
*출처: MIT Technology Review
또한 학습 및 추론 과정에서도 할루시네이션은 발생합니다. LLM은 본질적으로 자신이 생성하는 내용을 이해하지 못하며, 인코딩/디코딩 과정에서 잘못된 상관관계를 학습하거나 특정 부분에 잘못된 가중치를 부여하여 엉뚱한 답변을 내놓기도 합니다. 또한, 모델의 매개변수(parameter)에 저장된 기존 지식(parametric knowledge)을 우선시하는 경향 때문에 개발자의 의도와 다른 답변이 생성될 수 있는 것입니다.
이처럼 기존의 생성형 AI 기술은 유창하고 자연스러운 문장을 만들어 내는 데에는 매우 효과적이지만, 동시에 한계를 내포하고 있습니다. 모델이 예측에 의존하기 때문에 실제 사실이나 맥락을 이해하지 못하고, 학습 데이터에 없는 내용을 유추하거나 그럴듯하게 꾸며낼 수 있기 때문입니다.
할루시네이션 방지를 위한 기술적 해결책
그렇다면 이처럼 고질적인 할루시네이션 문제를 해결하기 위해 현업 AI 엔지니어들은 어떤 방법을 모색하고 있을까요? LLM 자체의 구조를 바꾸는 연구도 활발하지만, 현재 가장 효과적으로 사용되는 방법들은 대부분 LLM의 외부에 안전장치를 마련하는 방식입니다. 할루시네이션 방지를 위한 대표적인 세 가지 방법론에 대해 소개하도록 하겠습니다.
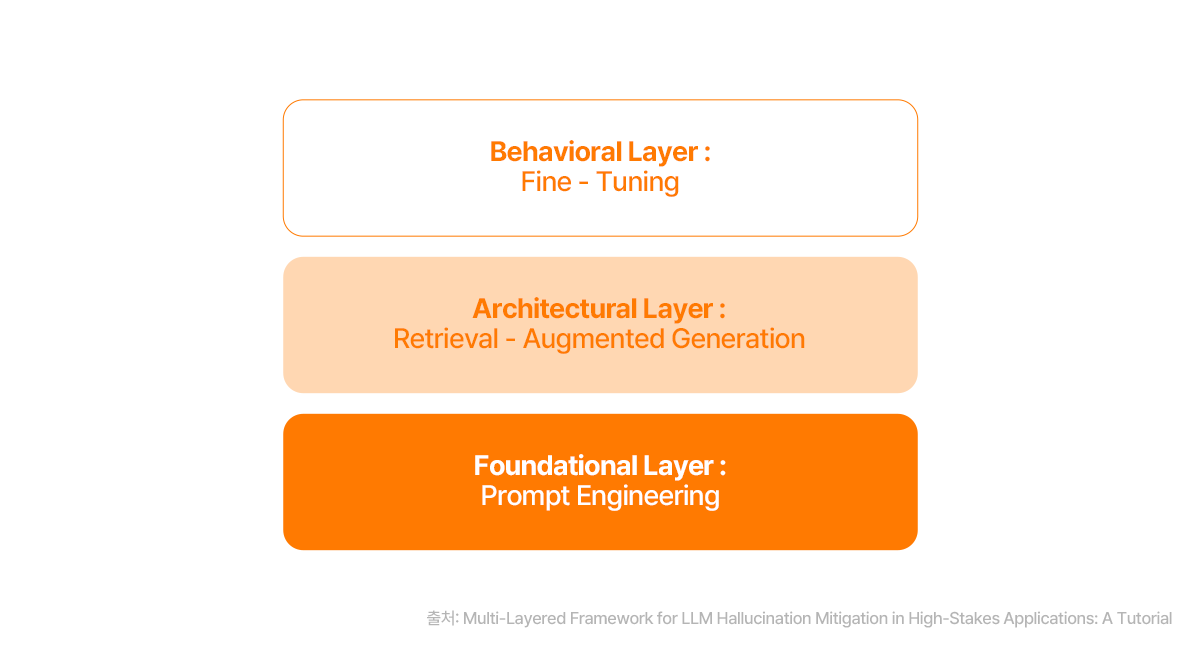
1. 프롬프트 엔지니어링 및 가드레일(Guardrails)
할루시네이션은 LLM에게 어떤 ‘지시(프롬프트)’를 내리느냐에 따라 크게 달라질 수 있습니다. 프롬프트 엔지니어링은 LLM의 할루시네이션을 줄이기 위해 질문을 명확하고 구체적으로 설계하는 기술입니다. 예를 들어, 모호한 질문 대신 “참고 자료를 바탕으로 답변해 줘”와 같이 명확한 지시를 포함하거나, 답변의 형식을 제한하는 것이 좋은 방법입니다.
또한, 가드레일(Guardrails)은 LLM의 출력값(Output)이 일정한 규칙이나 제약 조건을 벗어나지 않도록 통제하는 시스템입니다. 부적절하거나 잘못된 정보를 차단하고, 특정 사실에 기반한 답변만 허용하도록 설계하여 할루시네이션의 위험을 낮춥니다. 일종의 안전망 역할을 하는 셈입니다.
2. 외부 데이터 소스를 활용한 검색증강생성(RAG)
답변 생성 과정에서 API나 내부 지식 소스 등 LLM 자체가 아닌 외부의 데이터 소스를 활용하는 것이 가장 많이 알려진 할루시네이션 예방법이며, 그 중 가장 대표적인 기술이 바로 검색증강생성 (Retrieval Augmented Generation, RAG) 입니다. LLM이 외부의 신뢰할 수 있는 데이터베이스나 문서에서 필요한 정보를 검색한 뒤, 이를 바탕으로 답변을 생성하는 방식이라고 할 수 있습니다.
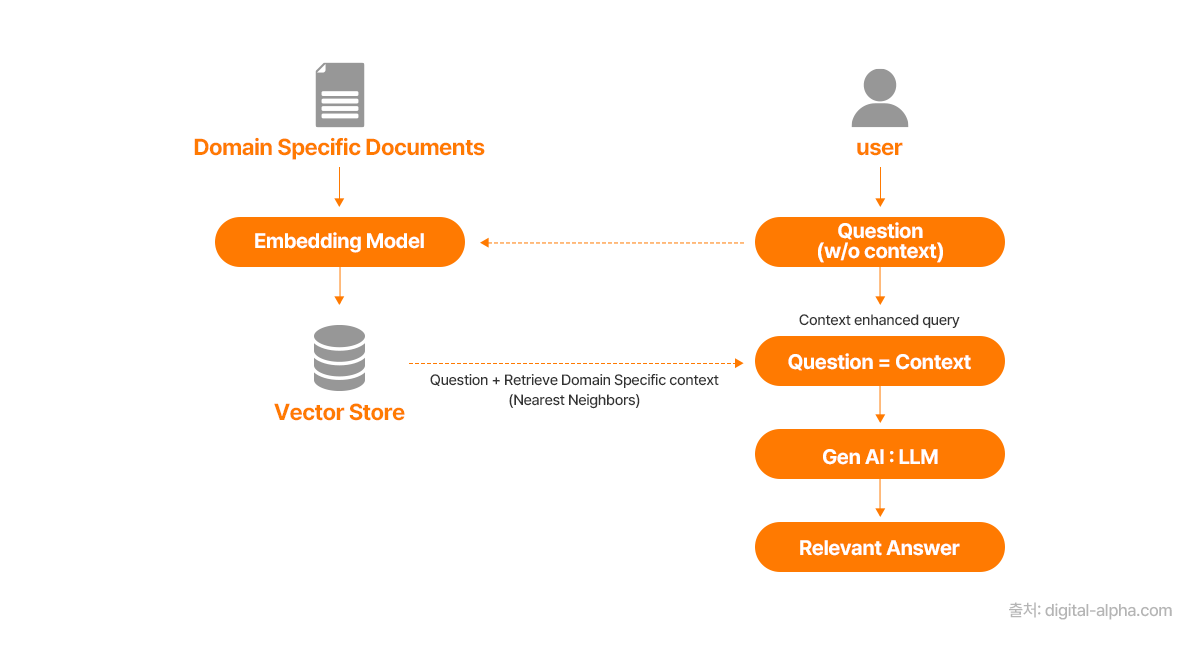
예를 들어, 특정 회사의 내부 문서에 대한 질문을 LLM에 던질 때, RAG 시스템은 먼저 이 내부 문서들을 검색하여 질문과 관련된 정보를 찾아냅니다. 그리고 찾아낸 정보를 LLM에 입력하여 제공하며, LLM이 해당 정보를 기반으로 답변을 생성하도록 유도합니다. 이를 통해, LLM이 학습 데이터에 없는 최신 정보나 특정 도메인의 전문적인 정보를 다루면서도 할루시네이션을 줄일 수 있습니다. RAG는 LLM의 지식 범위를 확장하고 정확성을 높이는 효과적인 기술로 평가받습니다.
3. 모델의 미세 조정(Fine-tuning) 및 강화학습
LLM을 특정 도메인의 데이터셋으로 미세 조정하는 것 역시 할루시네이션을 줄이는 효과적인 방법이라고 할 수 있습니다. 예를 들어, 법률 분야의 LLM을 개발한다면 방대한 법률 문서를 추가로 학습시켜 해당 분야의 정확성을 높일 수 있습니다. 이를 통해, 모델이 특정 도메인에 대한 깊이 있는 지식을 습득하고, 사실에 기반한 답변을 생성하는 능력을 향상시키는 것입니다.
또한, 인간의 피드백을 활용하여 LLM의 답변을 교정하기도 합니다. 예를 들어, 인간 피드백에 의한 강화 학습(RLHF, Reinforcement Learning from Human Feedback)의 경우 모델이 사실과 다른 내용을 생성했을 때 페널티를 부여하고, 정확한 답변에 보상을 줌으로써 모델의 행동을 교정하는 방식으로 할루시네이션을 방지합니다.
AI 시대, 할루시네이션은 극복 가능한가?
지금까지 할루시네이션의 원인과 이를 해결하기 위한 기술적 노력들을 살펴보았습니다. 할루시네이션은 LLM이 내포한 본질적인 문제인 만큼 완전히 ‘0’으로 만드는 것은 매우 어려운 과제입니다. 하지만 앞에서 소개한 것과 같이 외부 데이터 소스의 활용이나 프롬프트 엔지니어링 및 가드레일 마련과 같이 다양한 기술적 접근법을 통해 그 발생 빈도와 심각성을 크게 줄일 수 있습니다.
특히 RAG와 같은 기술은 LLM의 활용성을 높이면서도 신뢰도를 확보하는 데 큰 역할을 하고 있습니다. 이를 활용하면 AI 에이전트 개발이나 비즈니스 의사결정과 같이 정확성이 중요한 분야에서 생성형 AI를 보다 안전하게 활용할 수 있습니다. 할루시네이션 문제를 해결하려는 노력은 단순히 LLM의 성능을 개선하는 것을 넘어, AI가 우리 사회에 더욱 깊숙이 신뢰성 있는 기술로 자리 잡는 데 필수적인 과정이라고 할 수 있습니다.
중요한 점은 할루시네이션을 단편적인 현상으로 이해하는 것이 아닌, LLM 작동 원리에 대한 이해를 바탕으로 접근하는 것이 중요하다는 것입니다. AI 기술의 발전과 함께 할루시네이션을 제어하는 기술 또한 끊임없이 발전하고 있습니다. 앞으로 새로운 기술이 등장하더라도, 명확하게 이해하고 효과적인 해결책을 찾아낸다면 할루시네이션을 극복할 수 있을 것입니다.
[참고자료]
- Digital Alpha Platforms, (Reducing LLM Hallucinations Using Retrieval-Augmented Generation (RAG))
- ResearchGate, (Role0play with Large Language Models)
- MDPI, (Multi-Layered Framework for LLM Hallucination Mitigation in High-Stakes Applications: A Tutorial)
- MIT Technology Review, (AI language models are rife with different political biases)
- Vellum, (GPT-5 Benchmarks)
AX 컨설팅부터 비즈니스 모델 발굴까지
Global Top 10 AX Service Company|SK AX




#생성형AI #LLM #Hallucination #할루시네이션 #환각현상 #RAG #프롬프트엔지니어링

![[리포트 다운로드] 통신운영의 새로운 게임 체인저 AI Native OSS | 3월 MI리포트](https://www.skax.co.kr/wp-content/uploads/통신-지속혁신_600x400.png)
![[리포트 다운로드] ESG 공시의 변곡점: Reporting'에서 'Control'로 | 3월 MI리포트](https://www.skax.co.kr/wp-content/uploads/ESG-AI플랫폼설계구축_600x400.png)
![[리포트 다운로드] AI 도입 패러다임의 전환: AI Product 기반 엔터프라이즈 맞춤화 전략 | 3월 MI리포트](https://www.skax.co.kr/wp-content/uploads/AI_600x400.png)